Zrychlování Ruby on Rails aplikace
Nikdo asi nepochybuje o tom, že je důležité, aby návštěvníkovi stránek došla odpověď od serveru co nejrychleji – jednak kvůli jeho spokojenosti, druhak kvůli schopnosti ustát nárazový příval návštěvníků.
Jenže při vývoji se často vůbec nepozná, že někde je úzké místo, které by mohlo působit problémy v reálném provozu, až budou v databázi stovky a tisíce záznamů. A stejně jsem k tomu přišel i já. Při vývoji bylo všechno naprosto bezproblémové, ale za 3–6 měsíců v ostrém provozu se nashromáždilo tolik dat, že se úzká místa začala negativně podepisovat na odezvě aplikace. Když jsem začínal problémy poprvé řešit, byla průměrná odezva na požadavek 10–15 vteřin. Při druhém řešení již 15–20. Když jsem aplikaci testoval na jiném serveru, tak dokonce 35 vteřin! Na vývojovém stroji byly běžné časy i 40–60 vteřin. Zkrátka bída.
Nejrychlejším řešením je v takovém případě cachování odpovědí do statických HTML souborů, pokud to povaha webu umožňuje. Když má člověk možnost ovlivnit přepisovací pravidla svého webu (mod_rewrite u Apache), není problém cachovat i odpovědi na požadavky s parametry v URL (tzv. query string). Samozřejmě to pak vyžaduje vlastní cachovací metody, protože tohle Railsy v základu neumí.
Nicméně cachování neřeší podstatu problému. Stejně někde je úzké místo a stejně na něj někdy přijde řada, když daný požadavek žádnou cachovanou odpověď mít nebude nebo ji bude mít zneplatněnou.
V tento moment jsem si vzal aplikaci a ostrá data a podle časů jednotlivých SQL dotazů, které se často prováděly, vytvořil nad databází příslušné indexy. Začínal jsem s časem „ActiveRecord: 22485.3ms“ a skončil „ActiveRecord: 3344.2ms“. Díky tomu, že těch dotazů bylo opravdu hodně, tak to udělalo takovýhle rozdíl.
Když je databáze optimalizovaná, přijde na řadu profilování vlastního kódu. Railsy sice něco nabízejí – jisté performance unit testy, ale příliš jsem nepochopil, k čemu jsou dobré, když jejich výstup je nicneříkající:
BrowsingTest#test_homepage (72 ms warmup)
process_time: 65 ms
memory: unsupported
objects: unsupported
.
Finished in 4.701334 seconds.
3 tests, 0 assertions, 0 failures, 0 errorsVím akorát, že zpracování trvalo 65 milivteřin a zážeh 72 milivteřin. Ale kde byly propáleny, ne. Po pár marných snahách tomu přijít nakloub, jsem to vzdal a vyzkoušel jiné řešení, na které jsem narazil, – New Relic.
Nic se nebojte, ač se všude píše o nutnosti registrace, tak to není tak žhavé. Se základní verzí, která je zdarma, se dá docela dobře vystačit. Tak v prvé řadě nainstalovat gem newrelic_rpm, zahrnout do Gemfile (bude potřeba v development), ze složky s gemem (u mě /usr/lib/ruby/gems/1.8/gems/newrelic_rpm-3.1.1/) si zkopírovat soubor newrelic.yml do složky config/ a náležitě upravit (hlavně nastavit v sekci Application Environments položky monitor_mode a developer_mode na true). A pokud jedete na passengeru, tak omezit počet instancí aplikace na 1. Pak už jen restart aplikace a jede se. Není potřeba nikde nic zapínat, monitoruje se to automaticky, výsledky jsou dostupné na http://localhost:3000/newrelic.
Ze začátku se mi to zdálo nesnesitelně pomalé, ale později jsem zjistil, že to úzce souviselo s pomalostí mé aplikace. Člověk se dozví řadu zajímavých informací. Například jsem nevěděl, že při jednom požadavku má aplikace vykonává téměř 3.200 SQL dotazů. Na snímku níže je vidět, že vykonání všech těchto dotazů trvá značnou část z celkové doby zpracování požadavku. V kartě [SQL] jsou dva tisíce z nich vypsané a člověk se může rovnou prokliknout do kódu, přímo na řádek, kde se daný SQL dotaz vykonává.
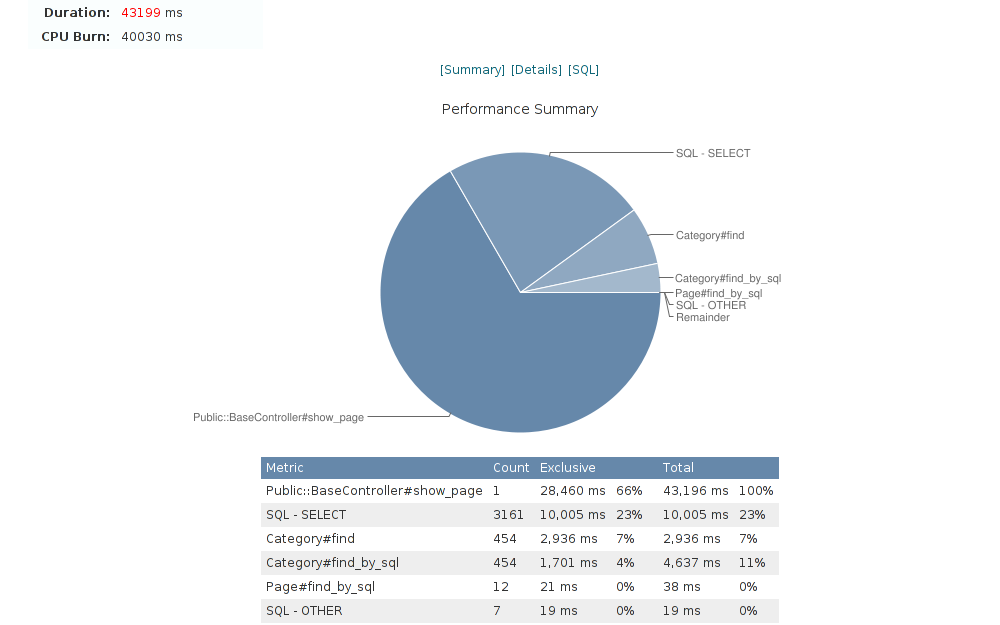
Zjistil jsem, že ono úzké místo v daném požadavku bylo vlastně jen v jedné jediné metodě. V zásadě byl problém v tom, že se načetla sada záznamů a nad nimi se prováděly nějaké databázové operace v rámci asociací – například zda kategorie (nebo nějaká její podkategorie v libovolné hloubce stromu) obsahují alespoň jeden produkt, a ten produkt zda patří do hlavního sortimentu či do doplňkového. Přepsal jsem ji vlastně do „PHP stylu“, jak tomu pracovně říkám, – nejprve si načtu všechny kategorie, uložím pěkně do hashe, pak všechny produkty a jejich rozdělení na hlavní/doplňkový sortiment, a teprve pak s tím vším pracuji.
Mnohdy není třeba se k „PHP stylu“ uchylovat, ale stačí (a leckdy je to naopak jediná smysluplná cesta) přednačíst příslušné asociace. I to celkem spolehlivě zabije jednoho žrouta výkonu.
Výsledek mne samotného překvapil:
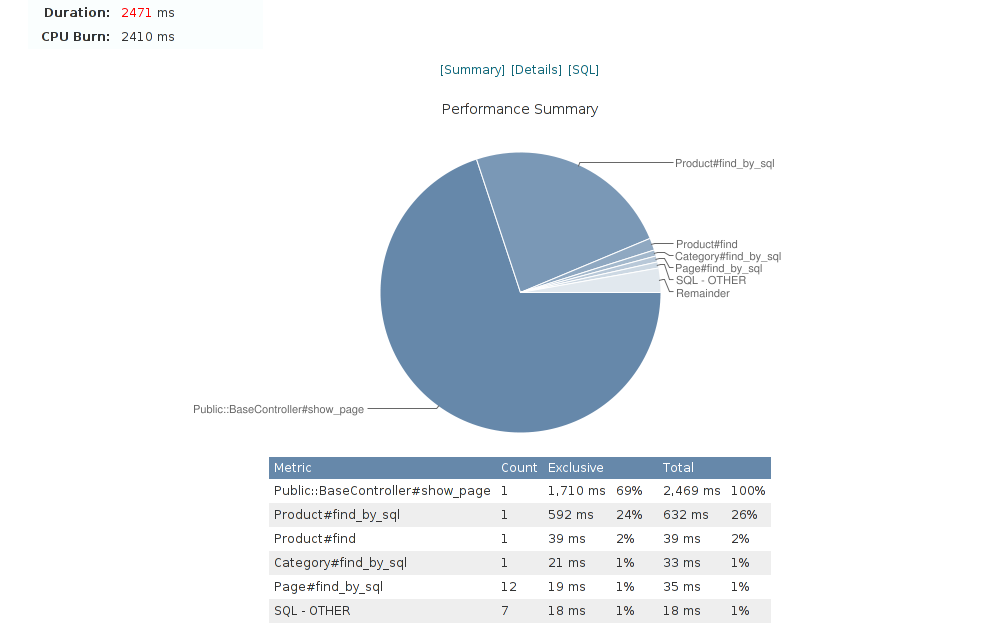
Ze 40 na 2,5 vteřiny. A to je ve vývojovém prostředí – na ostrém serveru jsem nerozlišil odpověď dynamicky generovanou aplikací od té, které šla z cache na disku. Současně jsem ještě přidal několik indexů do databáze – na dotazy, které už v kódu více zoptimalizovat nešly.
A stejným způsobem je potřeba zoptimalizovat všechny druhy požadavků na aplikaci. Teprve pak si člověk může oddychnout a spokojeně odeslat změny na server.
Co mě na celé věci těší, jak je snadné hledat úzká hrdla (a odstraňovat je) v Railsové aplikaci.
Zaškatulkováno v kategorii: Ruby on Rails | 10. září 2011